

はじめまして!
シミヅですっ!
この度、この「エンジニアの流儀」で記事を書かせていただくことになりました。
よろしくお願いしますっ!
「AIエンジニア」なんて名乗ってると、さぞかし難しい数式を毎日こねくり回してるんだろうなーって思われがちなんですけど、実は一番お世話になってるのって、意外と基礎的なアルゴリズムだったりするんですよね。
その代表格が、今回お話しする「ロジスティック回帰」なんです!
「名前は聞いたことあるけど、回帰なの?分類なの?どっちなのっ!」って混乱しちゃう方も多いはず。
今日はPythonを使って、そのあたりをスッキリ解決していきましょうー!
|
ロジスティック回帰って何?(回帰なのに分類なんです!)
まず最初に、これだけは声を大にして言いたいんですけど……。
ロジスティック回帰は、名前に「回帰」ってついてるのに、実際は「分類」のためのアルゴリズムなんですっ!
ややこしいですよね(笑)。
例えば、
- 「このメールはスパムか、そうじゃないか」
- 「この画像に写っているのは猫か、犬か」
みたいな、2つのグループに分ける(2値分類といいますっ)時にめちゃくちゃ力を発揮します。
仕組みをざっくり説明すると、「ある事象が起こる確率」を0から1の間で予測して、「0.5以上ならクラスA!」「0.5未満ならクラスB!」って判定しているんですよ。
魔法の仕組み「シグモイド関数」を直感的に理解しよう
ここで登場するのが、「シグモイド関数」です。
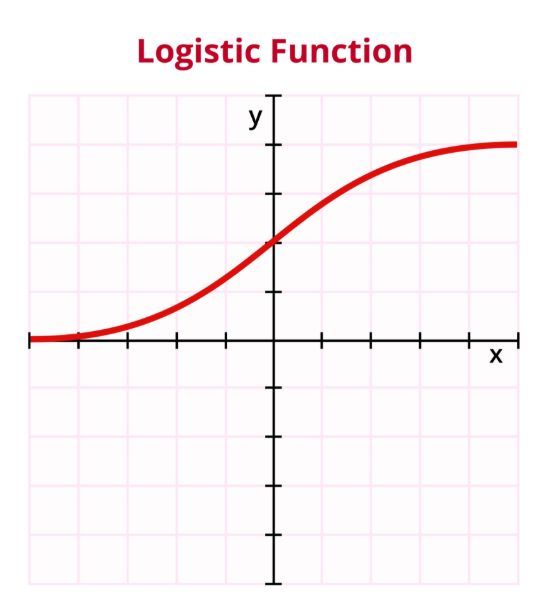
「数式で見ると頭が痛くなるっ!」という方のために、めちゃくちゃ噛み砕いて説明しますね。
この関数、どんなに大きな数字(100万とか!)を入れても、逆にどんなに小さなマイナスの数字(マイナス100万とか!)を入れても、答えを必ず「0から1の間」にギュギュッと押し込めてくれる魔法のようなフィルターなんです。
グラフにすると、アルファベットの「S」のような形をしています。
この「0から1」という答えを、私たちは「確率」として使っているわけですね。
例えば、「このメールがスパムである確率は0.8(80%)ですよー!」とシグモイド関数が教えてくれたら、「じゃあ0.5を超えてるからスパムだっ!」と判定する。
これがロジスティック回帰の正体なんですっ!
なぜPythonでロジスティック回帰を学ぶべきなの?
理由はズバリ、「シンプルで強力だから」です!
最近はDeep Learningとか派手な手法も多いですけど、ロジスティック回帰は計算が圧倒的に速いし、何より「なぜその結果になったのか」という解釈がしやすいんですよね。
実務でも「とりあえずロジスティック回帰でベースラインを作ってみよう」ってなることが本当に多いんですよー。
いわば、AI開発における「定規」みたいな存在ですね!
さらに、Pythonなら強力なライブラリ「Scikit-learn」があるから、複雑な計算を自分で書かなくても数行で実装できちゃうんです。
最高ですよね!
Pythonでロジスティック回帰を実装してみよう!
さあ、お待たせしましたっ。
実際にコードを書いていきましょう!
今回は、みんな大好きScikit-learn(サイキット・ラーン)を使って、サクッと実装しちゃいます。
まずは、ライブラリのインポートからですね。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score, confusion_matrix次に、実験用のデータを作って学習させてみますっ!
# 1. テスト用のデータを作成(2つのクラスに分類するデータ)
X, y = make_classification(n_samples=100, n_features=2, n_redundant=0,
n_clusters_per_class=1, random_state=42)
# 2. データを「学習用」と「テスト用」に分ける!これ大事ですっ
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. ロジスティック回帰のモデルを作る
model = LogisticRegression()
# 4. 学習開始!
model.fit(X_train, y_train)
# 5. 予測してみる
y_pred = model.predict(X_test)
# 6. 結果を確認!
print(f"正解率は... {accuracy_score(y_test, y_pred) * 100}% でしたっ!")ね?
めちゃくちゃ簡単じゃないですか!?
model.fit() で学習して、model.predict() で予測する。
この流れさえ覚えちゃえば、他のアルゴリズムでも応用が効くのがPythonのいいところなんですよ。
実際にPythonでロジスティック回帰を使う時の注意ポイント
ここで、僕が実務で「おっと、危ない!」ってなったポイントを共有しちゃいますね。
ここ、試験に出ますよー!(笑)
特徴量のスケーリング(単位を揃える!)
ロジスティック回帰は、データの値の範囲(スケール)がバラバラだと、うまく学習が進まないことがあるんです。
例えば、片方のデータが「0.1単位」なのに、もう片方が「100万単位」だったりすると、モデルが大きな数字にばかり気を取られて、小さな数字を無視しちゃうんですね。
StandardScaler とかを使って、平均0、分散1に揃えてあげると、モデルがもっとハッピーになりますよっ!
多重共線性(マルチコ)に注意
これ、ちょっと難しい言葉ですけど重要です!
説明変数の中に、お互いに強い相関があるもの(例えば「身長」と「座高」みたいに、一方が決まればもう一方もだいたいわかるような関係)が混ざってると、モデルの予測が不安定になっちゃうんです。
「どの変数が予測に貢献しているか」を正しく判断できなくなるので、似たようなデータはあらかじめ整理しておくのがシミヅ流の鉄則ですっ。
まとめ:ロジスティック回帰はAIエンジニアの親友です
ロジスティック回帰は、シンプルだけど奥が深くて、どんな現場でも一線級で活躍してくれるアルゴリズムです。
「回帰という名の分類器」、そして「シグモイド関数による確率予測」。
この2つを抑えるだけで、あなたのデータ分析スキルはグンと上がりますっ!
「まずは動かしてみること」が一番の上達の近道なんですよ。
皆さんも、手持ちのデータでぜひ試してみてください!
「できたっ!」っていうその感動が、エンジニアとしてのモチベーションになりますからね。
もし「ここがもっと知りたい!」とかあれば、いつでも聞いてくださいっ!
次は、このモデルをどう評価するか(混同行列とかね!)
……なんてお話もできればいいなーって思ってます。
それじゃあ、また次の記事でお会いしましょうー!シミヅでしたっ!




コメント